
Navigating privacy in a data-driven world with Microsoft Privacy
Data protection and privacy have become business imperatives. In a global survey conducted by Microsoft and leaders in the academic privacy space, 90 percent of respondents said they would not buy from an organization that does not properly protect its data.1 More than ever, people are highly aware of their privacy, digital footprint, and, most importantly, how the organizations they work with treat both. According to Gartner®, by the end of 2024, three-quarters of the world’s population will have personal data covered by modern privacy regulation.2
People exercise their privacy rights either explicitly, through actions like subject rights requests, or implicitly, through declining to do business with organizations they do not trust. For organizations committed to respecting the privacy rights of individuals, it can be challenging to implement requirements and controls needed to meet data privacy needs
Now generally available: The new Microsoft Dynamics 365 Customer Insights
At Microsoft Inspire 2023, we announced that we are bringing together Microsoft Dynamics 365 Marketing and Microsoft Dynamics 365 Customer Insights into one offer, enabling organizations to unify and enrich their customer data to deliver personalized, connected, end-to-end customer journeys across sales, marketing, and service. We are retaining the existing “Dynamics 365 Customer Insights” name to encompass this new offer of both applications. Today, we’re excited to share that the new Dynamics 365 Customer Insights is now generally available for purchase.
For our existing Dynamics 365 Marketing and Dynamics 365 Customer Insights customers, this change signals an acceleration into our “better together” story, where we’ll continue to invest in new capabilities that will enable stronger, insights-based marketing read more…
IDC shares how generative AI transforms business processes within marketing, sales, and service
Delving into the realm of customer-centric strategies, IDC analyst Gerry Murray casts a visionary light on the transformative influence of generative AI (Gen AI) on sales and service. Murray’s perspective resonates powerfully with the groundbreaking nature of Gen AI, which is reshaping customer interactions into a new era of efficiency and effectiveness.
Gen AI isn’t just another technology; it’s a strategic leap that orchestrates seamless data and workflows across marketing, sales, and service touchpoints
Microsoft and Epic expand AI collaboration to accelerate generative AI’s impact in healthcare, addressing the industry’s most pressing needs
Today, the promise of technology to help us solve some of the biggest challenges we face has never been more tangible, and nowhere is generative AI more needed, and possibly more impactful, than in healthcare. Read More…
Whisper: Revolutionizing Automatic Speech Recognition with Highly Trained, High-Performance OpenAI Technology

Hope you have liked my earlier blog ‘Next Generation ChatBot using OpenAI’s ChatGPT vs. Google’s Bard vs. Writesonic’s Chatsonic’. Pleased to introduce my next blog on OpenAI-whisper. Open AI’s Whisper is a general-purpose, multi-tasking, Automatic Speech Recognition model (ASR) that can perform multilingual speech recognition, speech translation, language identification and voice activity detection. It has been trained on 680,000 hours of multilingual, supervised, and diverse audio data collected from the web. Use of such a large and diverse dataset leads to improved human level robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English.
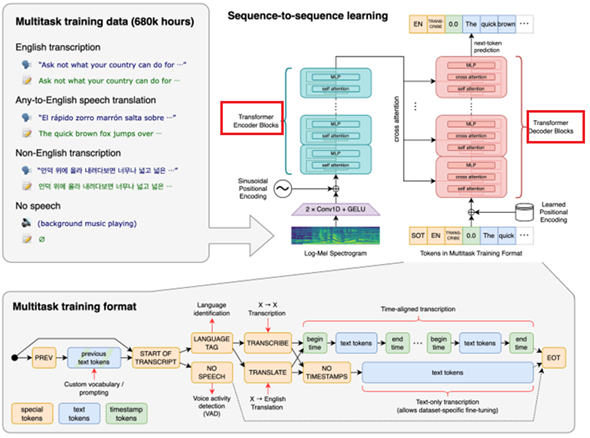
The basic building block of Whisper models is a Transformer (Paper ‘Attention is all you need’ published in 2017 by Mr. Ashish Vaswani and 7 team members). The Transformer is a model architecture suited for solving problems containing sequences such as text or time series data. The architecture facilitates parallel computing and captures long range dependencies far better and more effective than the conventional RNN models thereby making it a high performing. Can be trained on a larger data set leading to high accuracy in responses. It has also been a basic building block for Open AI’s GPT series models and DALL-E models, Google’s LaMBDA and PaLM Models. It works on ‘Self Attention’ mechanism explained in diagram herewith.
It consists of Encoder and Decoder (In image, marked with RED boundaries) both having multiple layers of ‘Self Attention’ and Feed Forward Neural Network. The Encoder takes the text input (Called as Prompt), tokenize it, assign weightage to each token, analyses, and performs downstream tasks like context Summarization, Language Generation, Sentiment Analysis, Translation and many more. The Decoder uses context summary to create a response from the model.
The tasks in Whisper Models are jointly represented as a sequence of tokens to be predicted by the decoder, allowing a single model to replace many stages of a traditional speech-processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
As of today, OpenAI has introduced Whisper with the following models.
| Size | Layers | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
| tiny | 4 | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 6 | 74 M | base.en | base | ~1 GB | ~16x |
| small | 12 | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 24 | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 32 | 1550 M | N/A | large | ~10 GB | 1x |
- The file upload has been currently limited to 25 MB.
- For longer inputs, break the file into chunks of each not more than 25 MB.
- It supports a fairly long list of input file formats such as mp3, mp4, mpeg, mpga, m4a, wav and webm.
- As of today, it can translate or transcribe audio from long list of around 98 languages but into English only.
- The model performance and accuracy are accessed using Word Error Rate (WER).
- The figure below shows WER language wise on a Large-V2 Model. The smaller the number, the better the performance.
- In the following figure, performance of only those languages have been shown for whom WER < 50%.
Implementing OpenAI’s Whisper:
- Pre-requisite:
- An Open AI account (Signup to platform.openai.com)
- Secret Key (Follow steps to generate a new OpenAI secret key)
- Development IDE (Something like Microsoft Visual Studio Code)
(Reference: https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key)
2. Install OpenAI Python SKD…
- The command is pip install openaiFor upgrading, pip install upgrade openai
- For installing Whisper: pip install openai-whisper
3. Define secret key…

4. Declare necessary imports…
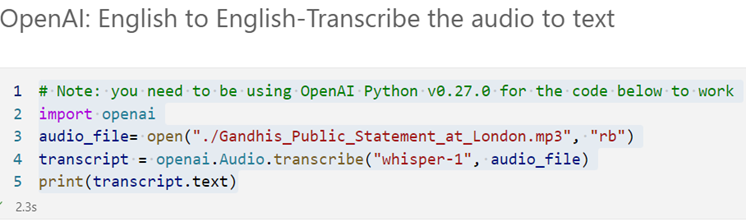
5. Submit an audio file to transcribe it into English.
6. Submit the German audio file to translate it into English!

Output:

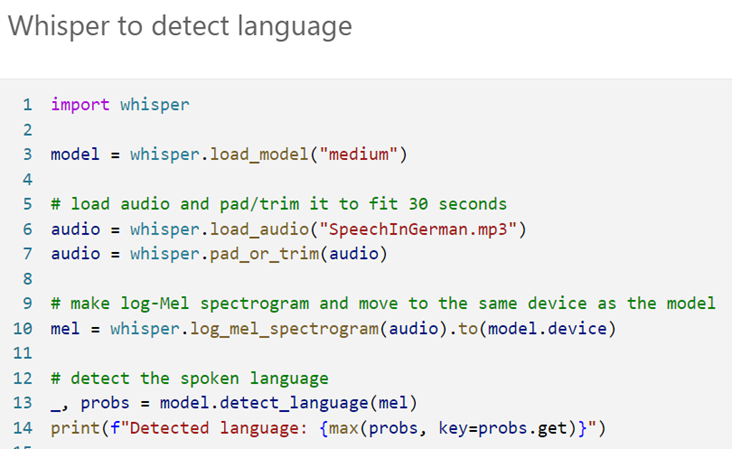
7. Whisper to detect language.
8. Whisper to transcribe audio.
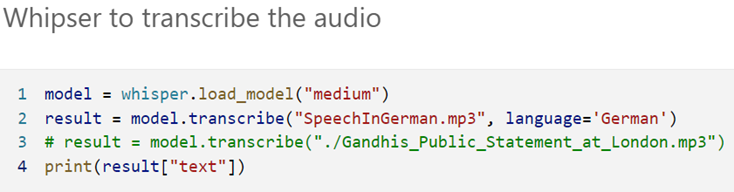
9. Working with Longer Inputs: Split large file into smaller chunks

10. Translate a chunk or multiple chunks in loop…

Though under development, the feature will be extremely useful in future to do quick transcription and translation. It can take responses of ChatGPT or its responses can be used into ChatGPT or other models of OpenAI like DALL-E. Obviously, inter-model communication can take the technology to next high level by enabling solutions for complex problems and leveraging power of technology to augment responses with innovation. With ChatGPT 4, where you see all features of OpenAI under one roof including Whisper, will discuss in my next blog. Expecting your comments on the blog and keep reading my upcoming blogs. Thanks.
Microsoft and Epic expand AI collaboration to accelerate generative AI’s impact in healthcare, addressing the industry’s most pressing needs
Today, the promise of technology to help us solve some of the biggest challenges we face has never been more tangible, and nowhere is generative AI more needed, and possibly more impactful, than in healthcare. Epic and Microsoft have been paving the way to bring generative AI to the forefront of the healthcare industry. Together, we are working to help clinicians better serve their patients and are addressing some of the most urgent needs, from workforce burnout to staffing shortages.
We combined Microsoft’s large-scale cloud and AI technologies with Epic’s deep understanding of the healthcare industry

3 ways mixed reality empowers frontline workers
Manufacturers worldwide invest heavily in digital transformation, overhauling almost every aspect of their operations and business models. But one key group—frontline workers —are still awaiting their digital renaissance.
Today, many organizations feel their workers are not empowered or digitally well-equipped. Manufacturers struggle with high turnover and the challenge of training and upskilling new workers. Downtime and worker productivity remain nearly universal issues.

To help address these issues, Microsoft invests in frontline worker enablement across a broad range of technologies. This includes new solutions to help
Microsoft solutions boost Fortune 500 frontline productivity with next-generation AI
Frontline workers represent the face of organizations and make up the lion’s share of the workforce. Gartner estimates there are 2.7 billion frontline workers — more than twice the number of desk-based workers.i The current macroeconomic climate highlighted by labor and supply chain shortages have put a lot of pressure on these workers to carry more work as organizations drive efficiency across business operations.
The future of business is here: How industries are unlocking AI innovation and greater value with the Microsoft Cloud
Over the past six months, I have witnessed the staggering speed and scale of generative AI technology adoption, and how it has opened doors for organizations to imagine new ways to solve business, societal, and sustainability challenges.
OpenAI’s DALL.E Implementation using Python.
- Pre-requisite:
- An Open AI account (Signup to platform.openai.com)
- Secret Key (Follow steps to generate a new OpenAI secret key)
- Development IDE (Something like Microsoft Visual Studio Code)
(Reference:https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key)
2. Install OpenAI Python SKD
- The command is pip install openai
- For upgrading, pip install upgrade openai
- For installing Whisper: pip install DALL-E
3. Define secret key…

4. Declare necessary imports.
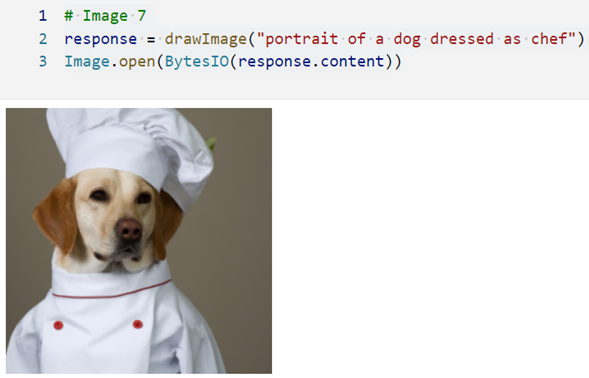
5. Declare a re-usable code…
Observe, ‘openai.Image.create() takes parameters and create an image. Obviously, the Prompt is expected parameter while ‘n’ represents the number of images to be created. Smaller is the size of the image, less is the response time.

6. Create an image giving a text prompt.

7. Image Editing: It takes an image and a masked image. It maps both images to identify the area to modify as per given Prompt. Note, masked area is places with Flamingo and masked area around Flamingo is filled from original image.

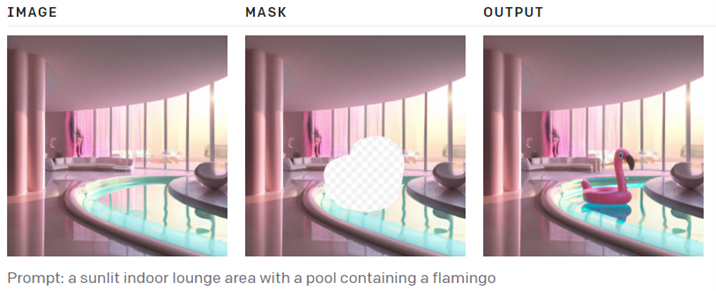
8.Variations in the given image: Observe the factor ‘n’ which decides number of varied images to create.


9.Azure OpenAI Studio and using its DALL·E Playground.
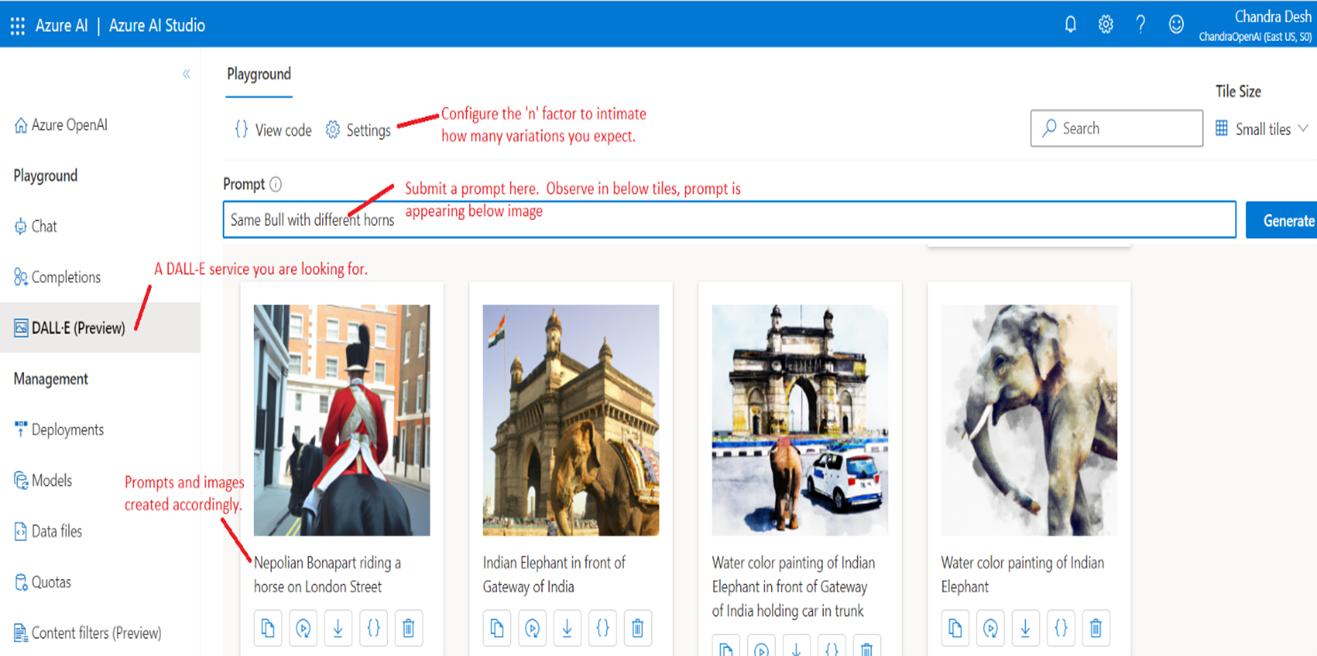
10.Following are few of the Prompts submitted to it and its responses. Hope you will enjoy them…

Creating a custom model of DALL·E 2
The Open AI’s DALL·E Studio offers easy way to process and transform images, create custom models by training them using transformed images and then testing them. Training an image generator with DALL·E 2 requires a few steps.
- You must obtain the dataset, which should contain images of different objects and activities.
- You must pre-process the dataset to ensure that the images are suitable for training. Images may need resizing, cropping, flipping, and rotating the images.
- You must then create the training model. This model should be optimized for the specific dataset and task you are training it for.
- Finally, once the model is created and trained, you can use the DALL·E 2 API to generate images based on the training data. With proper setup and optimization, this process can be used to create high-quality images generated from the training data.
Our next blog on DALL·E will explain step-by-steps to create custom models. Till then get amazed and enjoy the journey to AI.
Machine Learning Operations (ML Ops)
-BY CHANDRASHEKHAR DESHPANDE (MCT, SYNERGETICS INDIA)
We are in the era of cut-throat competition among business houses in making quick, timely decisions with high and reliable precision and offering services to the utmost satisfaction to customers with the help of technologies like Machine Learning, Artificial Intelligence, Chatbots, and so on. Data Science deals with a modern approach to processing a vast volume of data to find unseen patterns, and derive meaningful information to make business predictions and so, is becoming an essential part of ‘Data Driven Decisions’ for business houses today. It uses complex machine learning algorithms to build predictive models with the support of an ecosystem for voluminous storages capable of dealing with high-velocity data, distributed, high speed and scalable computing, deployment environment responding with minimal latency, data flow, and workflow management with tools to secure whole system. And above all, with the added feature of dealing with a variety of data sources/sinks with a variety of data formats. The life cycle of Data Science has been posing challenges for its complexity, demand for entirely different eco-system of tools and technologies, departments/teams working in silos, reusing and recycling of life cycle pipelines, and above all, keeping performance all-time high. Problems have always been a motivation for the corporate fraternity to find solutions and go ahead. The Model Ops/MLOps/AI Ops are innovations in this direction.
Need of ML Ops in the ecosystem–
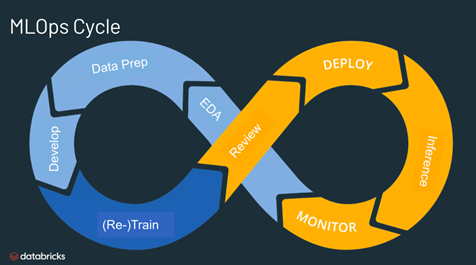
Productionizing the Data Science life cycle has always been difficult because it consists of many complex steps such as data ingestion, data preparation, model training, model tuning, model deployment, monitoring, explaining ability, and so on. Naturally, it requires stringent operational efforts to synchronize all these processes to make to work them in tandem. The ML Ops approach facilitates Continuous Implementation and Deployment (CI/CD) practices smoothly weaved with monitoring, governance, and validations over the ML Model life cycle. Thereby, it offers great help to Data Scientists, ML Engineers can smoothen the collaboration among them to increase the pace of development, deployment, and production. MLOps encompasses the experimentation, iteration, and continuous improvement of the machine learning lifecycle.
Once in production, the performance of ML model degrades specifically because it received new data with the new change of market trends, business practices, etc on which it is yet to be trained. Soon business realizes a need of retraining the model on new data to keep its performance always up to expectations. It becomes a never-ending cycle of training a model on new data regularly after a specific interval of time.
The MLOps is a machine Learning Operation intended to automate the process of applying life cycle steps of data science, taking machine learning models to production, maintaining and monitoring them all the time, accessing their performance, and when realizing that performance has been downgraded below the threshold, re-cycle them to create a re-trained and improved highly performing model based on recent data changed with trends.
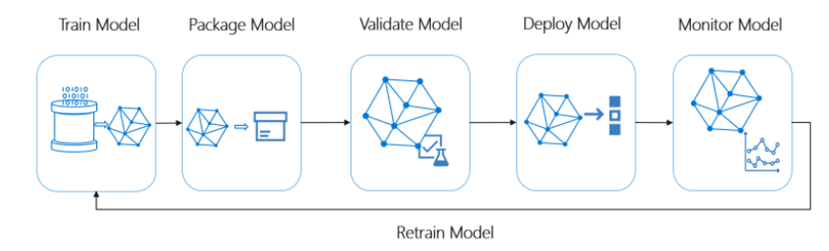
Features and Capabilities:
- Creating a re-producible ML Pipeline: A pipeline object can stitch together different steps like Data Cleaning, Preparation, Feature Extractions, Hyper Parameter Tuning, Model Evaluation, etc. Once created, an object can be deep cloned, used, or re-used as per need. In Azure ML Designer, the version of a pipeline can be created by copying it.
- Create Re-usable software environment: Environment describes ‘pip’ and ‘Conda’ dependencies of software requirements for Training, Testing, and Production environments. Tracks and builds software dependencies without manual intervention or hard-coded software configurations.
- Register Models from Anywhere: A ML Model registration service stores and versions the model automatically on the cloud and provides access all over the globe. It’s a logical container of one or multiple files uniquely identified by a name and the version. A model is accessible for deployment, download, search on tags, and adding a new version model.
- Package and Deploy Models: The model has packaged in Docker Image automatically while deploying on Kubernetes services. When deployed on Kubernetes services, multiple versions of endpoints can be created which allows Split/Bucket (A-B Testing) to compare the performance of multiple models by routing traffic to multiple endpoints.
- Support of Open Neural Network Exchange (ONNE): On conversion of the model into ONNE format which offers around double, uniform, and optimal performance on different hardware like CPU/GPU/FPGA and platforms like OnPrem/Cloud/Edge.
- Capturing Governance Data: Captures metadata to let us …
- Track end-to-end audit trail of all ML assets.
- Automatically maintains the versions and profile of data sets.
- When plugged with Git Hub, allows commit/branch the code snippets
- Interoperability allows model explanation and meets regulatory compliances.
- Maintains Run History with Snapshots of data, code, and compute used to train the model
- The Model Registry captures metadata of registered models.
- Notify and alert on events in ML Life Cycle by linking Azure ML with Azure Event Grid.
- Monitor ML Applications for operational and ML issues to understand the change in the performance of the model. Alerts can be raised on performance if goes below the threshold consistently for a significant duration. On alerts being raised, an automated pipeline can be triggered to retrain the model on new data, run evaluation and testing phases, and compare performances of the old and new models to decide whether to deploy a new model in the production environment.
- Design the CI/CD using GitHub and Azure Pipeline.
Major Steps of Implementation–

- Ingesting data from various data sources and accumulating in a Blob Storage: The Azure ML Data Store is an abstraction over the connection and secret details to connect to the Data Source/Sink. It identifies the data source/sink by a name and is attached to the Azure ML Workspace. The step exercises Extract Load and Transform to make data ready for consumption in Azure ML Service.
- Creating Azure ML Environment. If it is Python, an environment comprises Conda Dependencies declared through the configuration file and the Environment Object. The Configuration file declares Python Core Packages, external packages, and libraries like Sci-Kit Learn.
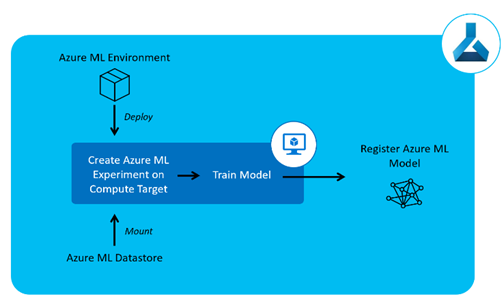
3. Model Training and Registration to Azure ML Registration service. This step includes training one or more models using different algorithms and/or the same algorithm with different sets of hyperparameters. Identify the best-performing one and register its object to the ML Registration Service. The registration service automatically manages and increments versions for the models registered with the same name. All the steps here are to be executed on the compute well equipped with a well-needed environment defined and created in step 2. For pulling the data for training and testing purposes, integration with the Blob Storage is again a need. The Data Store created in Step 1 is handy here to connect to Data Source and ingest the data from.
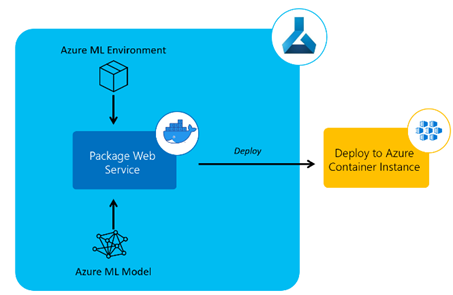
4. Model Deployment. Once the best-performing model is identified, it’s time to deploy it in Production Environment. There are two types of endpoints created around the model the way interaction is needed i.e. the Web Service endpoint and batch processing endpoint. Also, there are two types of Production Environments Azure Kubernetes Services and Azure Container Instances on which the ML Model can be deployed. For the Production Environment, it’s obvious that the Environment declared in step 2 must be submitted to create a similar environment to Model Training and Testing.
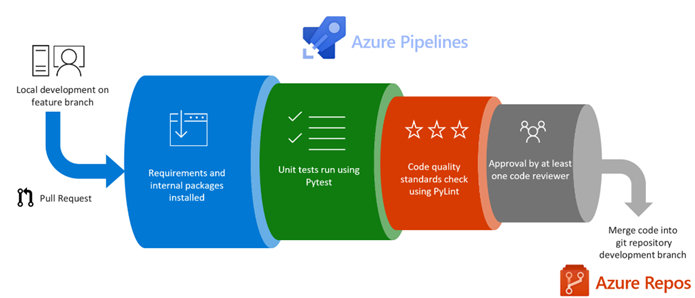
5. Continuous Integration and Deployment. The ML Pipeline is developed by writing code by members of a team, it’s essential to enforce the Unit Tests and Evaluation of Coding Standards. Whenever the user makes a PULL request on Git, the system must be automatically enforcing calls to the tools for Static Code Analysis and running of Unit Tests. The test results and code coverage must be published back to Azure DevOps for users before choosing to merge the code.
Wrap-Up:
ML Ops is a one-stop solution for different and many problems related to Machine Learning Life Cycle. It offers a compelling proposition to Businesses to run their ML Models. ML Ops streamlines the collaboration among teams and members by automating functions, and activities and thus reducing human interventions, and errors.
References:
- https://docs.microsoft.com/en-us/azure/machine-learning/concept-model-management-and-deployment
- https://www.researchgate.net/publication/357552787_MLOps_–_Definitions_Tools_and_Challenges
- https://benalexkeen.com/creating-end-to-end-mlops-pipelines-using-azure-ml-and-azure-pipelines-part-1 to part-7
- https://neptune.ai/blog/modelops
Microsoft Entra – New Identity Innovations (Part 1)
By Komal Sharma (MCT, Synergetics India)
Overview
In this modern era where most of the organizations have moved to digitalization, want every digital experience but can they trust it? During the pandemic when we were forced to work from home, security was the priority for everyone. How to manage the users and their access, was really a matter of concern. But what we have learned is that “Nothing is permanent but change”. All organizations are moving towards productivity and competence.
In this race, security is a concern and hence security team is under constant pressure since Resources and Identities are exposed or may be compromised. So, there is a question, how to come out of it? How to convert challenges into opportunities?
There is a need to find a solution to manage the Identity and access with less efforts & resources to connect to the world and to improve the performance of our organization.
Just imagine, if we can believe in every new digital experience and trust it blindly. Is it possible? Yes, now this is possible. Microsoft has introduced a new Identity and access product family – Microsoft Entra to overcome all our problems.
Many of you must be already using Azure Active Directory (Azure AD) as an Identity and access management solution in your organization. So, what’s new in Microsoft Entra? Entra is a family of all Identity and access products. All new capabilities related to Identity and access are on one portal.
Microsoft Entra Introduction

Microsoft introduced a new product for the family of Identity & Access management-related technologies. All related technologies are now under one roof. Entra leaves behind the traditional approach of Identity and access management and captures the future vision of IAM.
Entra includes Azure AD with permission management, CIEM which is cloud infrastructure entitlement management and Verified ID for decentralized identity management.
One thing to note here is, Azure AD is now a part of Entra but it doesn’t mean that it is renamed or replaced.
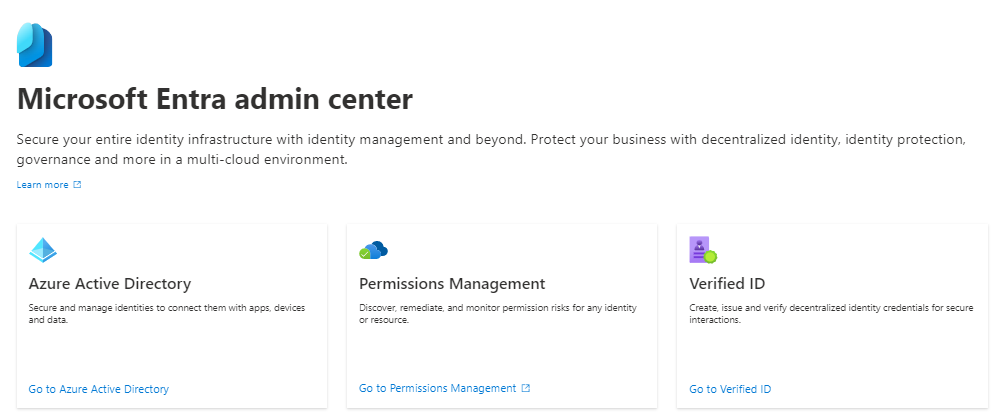
Microsoft Entra Product Family
There are three main members of the Entra product family:
1. Azure AD
2. Permission Management
3. Verified ID
Azure AD
Azure Active Directory is Microsoft Identity and access management solution that connects identities to their data, apps, and devices securely. Azure AD helps organizations to overcome modern identity and access management-related issues with:
1. Secure adaptive access
2. Seamless user experiences
3. Unified identity management
4. Simplified Identity governance

Azure AD protects identities with its core capabilities like Single sign-on, Multifactor authentication, conditional access, identity protection, privileged identity management and much more.
Permission Management
Entra Permission management was earlier a part of CloudKnox Permissions Management but now Microsoft has renamed it and made it an integral part of the Entra family. Permission management keeps an eye on all the permissions allotted to identities and controls them.

Microsoft Entra is a cloud infrastructure entitlement management service that not only penetrates and gets a deep understanding of Azure portal but AWS and Google Cloud Platform too.
The main features of Permission management are:
1. Get full visibility of resources that all identities are accessing.
2. Automate the principle of least privilege to make sure the right permission of identities at right time.
3. Implementing unified cloud access policies
Verified ID
We all are very aware of the concept of identity. We use identity proof while travelling, at hotels, offices, purchasing tickets and much more. This is where we need a decentralized identity. Nowadays we use our digital identity to make our mobiles, laptops, etc to be able to access our data. We know that these credentials are managed by some organizations or sometimes even we don’t. Microsoft Verified ID makes us believe in a standard base Decentralized identity concept that gives users and organizations a better experience to control their data.

There are three main roles in a Verifiable credential solution: User, issue and verifier.
1. User, who requests for a verifiable credential.
2. Organization that creates the solution that requests for information from the user to verify his identity, is the issuer.
3. A company that verifies claims from issuers they trust.
Microsoft Verified ID, a verifiable credential solution is based on some standards:
· Quickly onboard employees, partners, and customers
· Access high-value apps and resources
· Provide self-service account recovery
· Enable credentials to be used anywhere
What’s New to Entra?
There are two new products of the Entra family introduced in a trial mode and yet to be released publicly:
Microsoft Entra Workload Identities
We are very aware of Human identities but what is workload identity? Workload identities are apps, services, containers, etc that are granted to access our device data or communicate with other services. You can call them non-Human identities or software bots.
It helps organizations to protect their apps and services by enhancing security with conditional access, containing threats and reducing risk, reviewing all the users with implementation of least usage and getting more insight into workload identities.
Microsoft Entra Identity Governance
The security team’s main goal is to make sure that the right people have the right access in an organization. Entra identity Governance boost employee productivity and security and helps to meet compliance need. It automates the process of ensuring the right access to the right user at right time for the right services.
Core capabilities of Identity Governance with Entra are:
o Entitle Management
o Lifecycle workflow
o Access review
o Privileged Identity Management
Conclusion
I was very much thrilled when Microsoft announced Entra with its new capabilities. I have already been using Azure AD from the last few years and am excited to know what’s new about Entra as a new Identity innovation.
We can never imagine an organization in a secure boundary without overcoming the challenges of Identity and access. Nowadays when many of the organizations are opting for multi-cloud platforms. According to me, Microsoft Entra is a great option to bring all the Identity and access-related technology under one umbrella. Microsoft Entra helps them not only to overcome all the Azure identity management-related problems but also to keep in mind the multi-cloud concept too.
I liked Permission management which takes an insight into all your identity permissions and Verified ID that takes the vision of decentralized identity one step ahead.
Now, Microsoft Entra can meet head-on with organizations having a multi-cloud environment to secure, identify and access for a connected world.
How to set up Microsoft Entra Labs? In this blog, we’ve learnt what exactly is Microsoft Entra and what are the three main members of the Entra family. Now it is equally important that we learn how to set up Microsoft Entra Labs. Stay tuned with us to know how to set up the Entra Labs in part two of this blog.Source
https://www.microsoft.com/en-us/security/business/microsoft-entra
There are over one billion people in the world living with disabilities, and many face barriers to employment, education, and societal inclusion. In 2021, Microsoft launched a new five-year initiative to address these challenges by focusing on three priorities: developing more accessible technology, using this technology to create opportunities for people with disabilities to enter the workforce, and building a more inclusive workplace for people with disabilities. The goal is to bridge the disability divide and tap into the untapped talent pool of people with disabilities. Digital technology can play a crucial role in improving communication, interaction, and access to information for this community Read More...

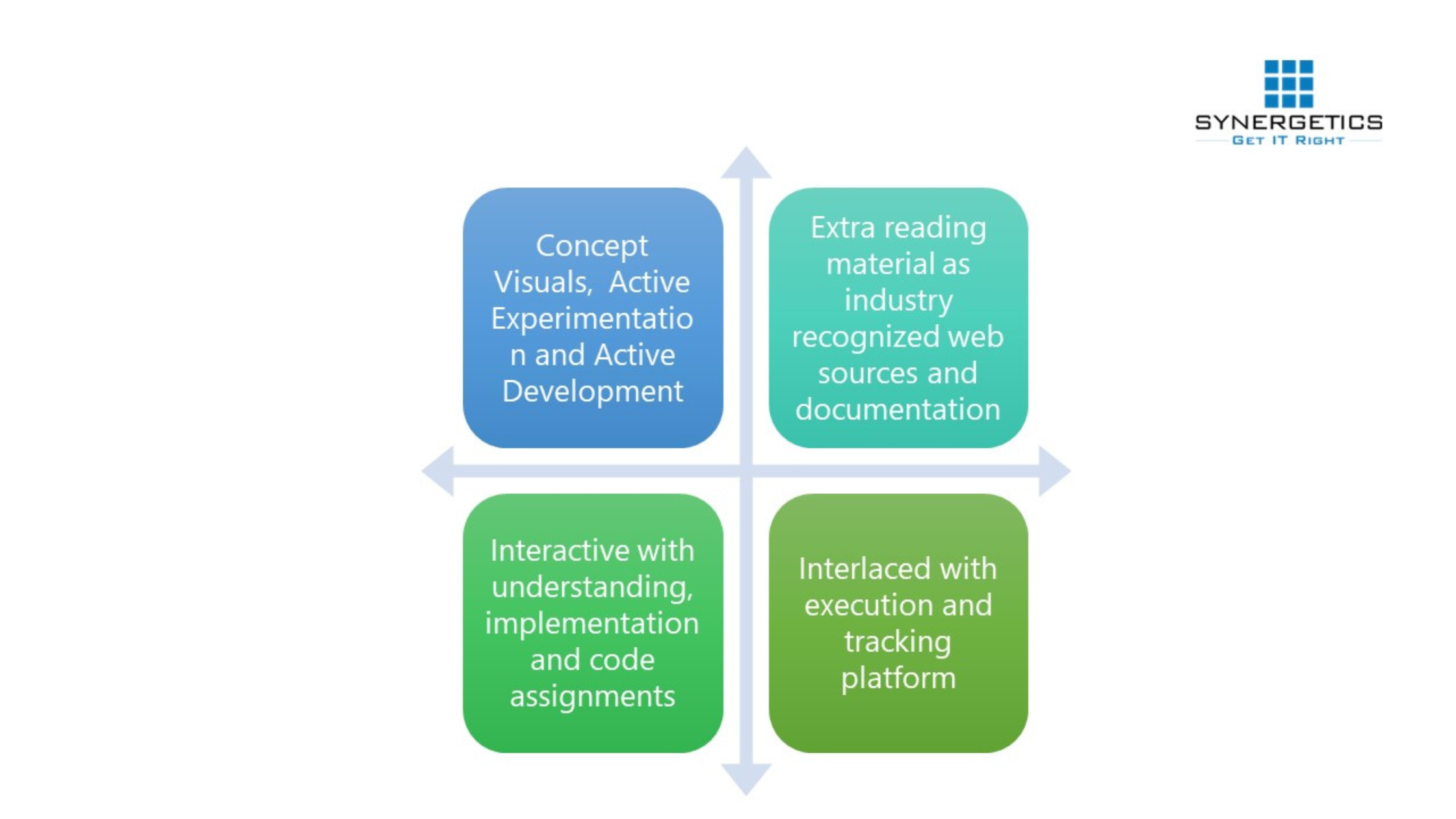
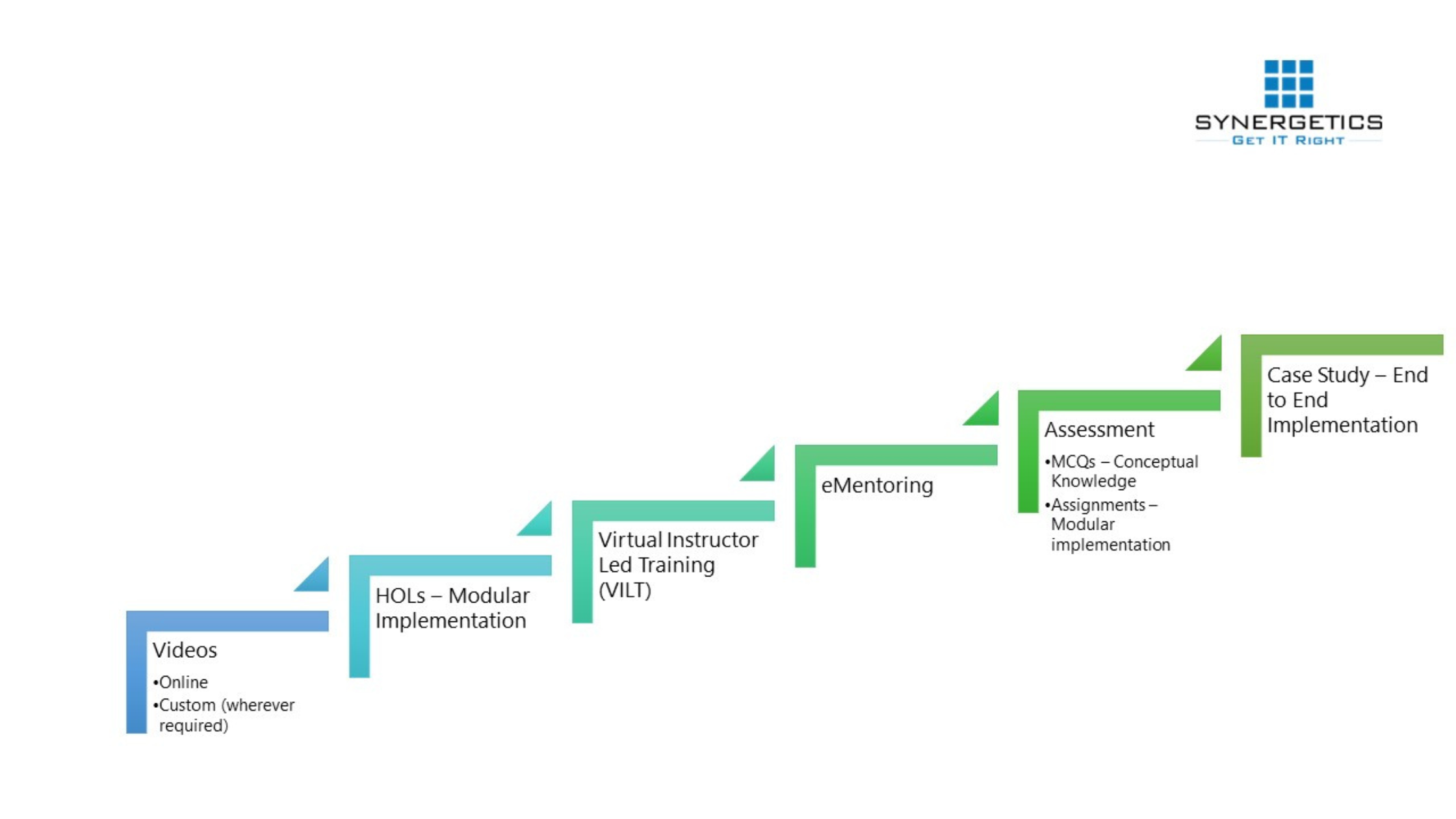
Transformation of a fresher to a certified IT resource – Approved and in-demand by the industry!

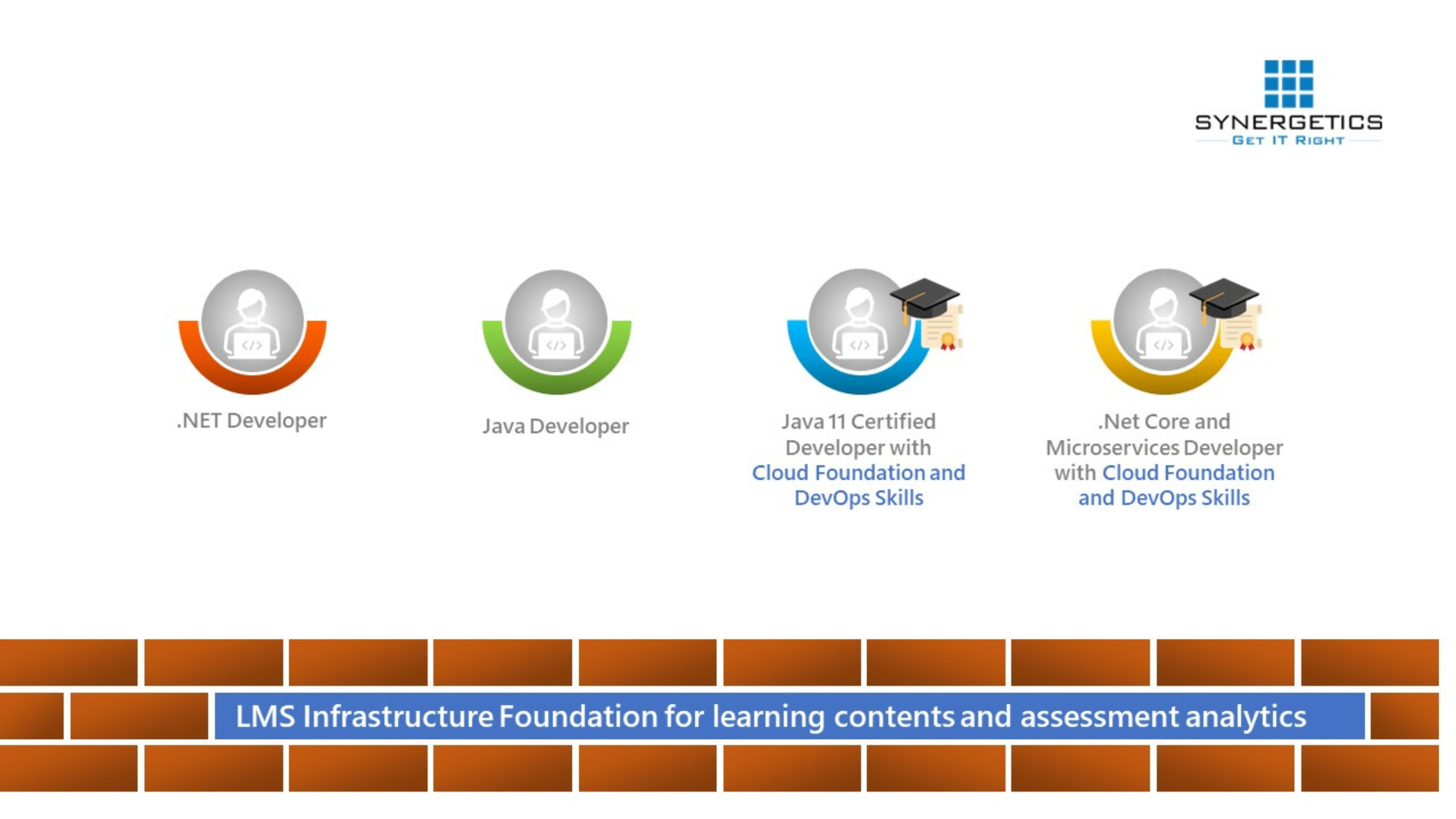
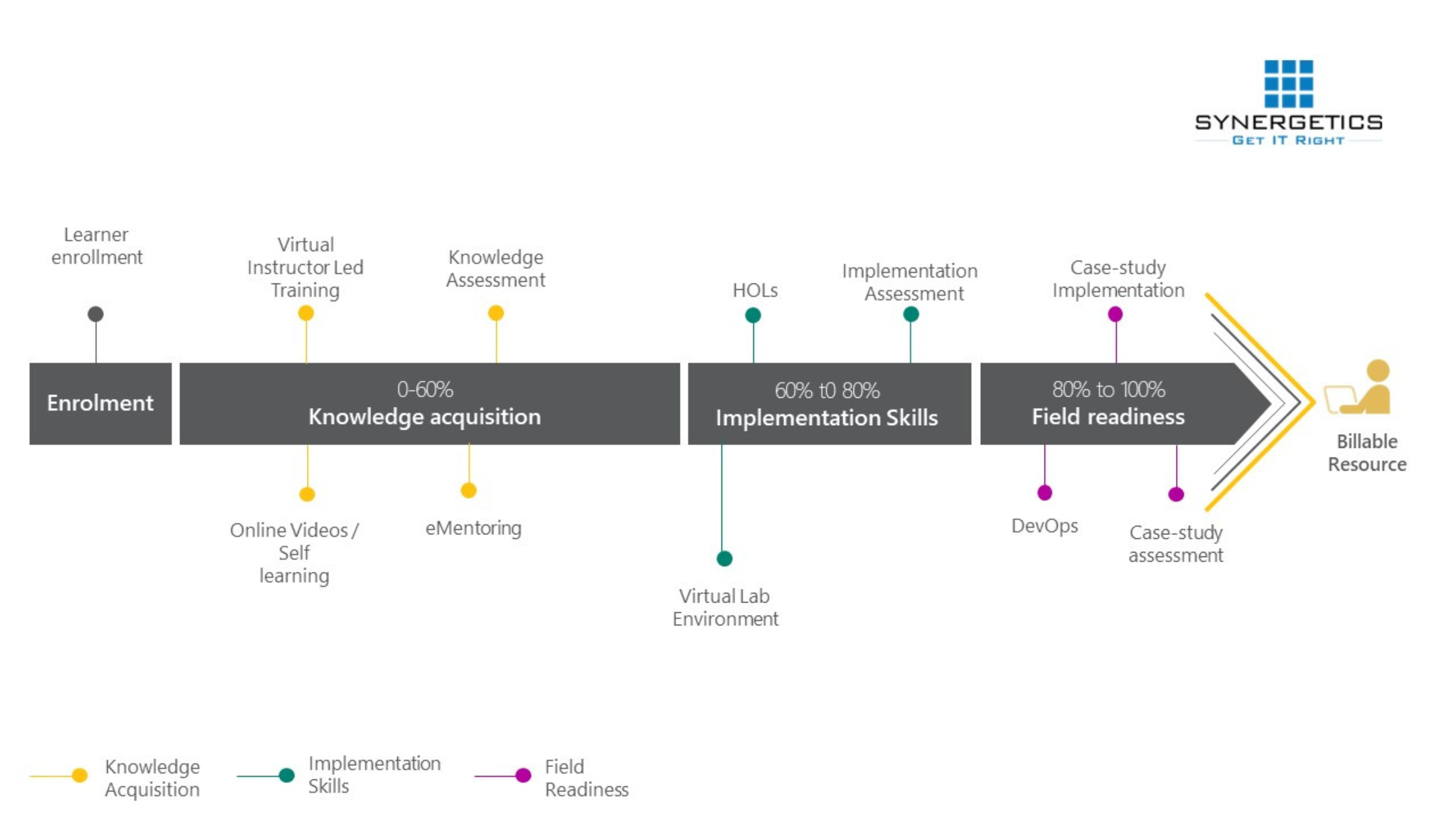
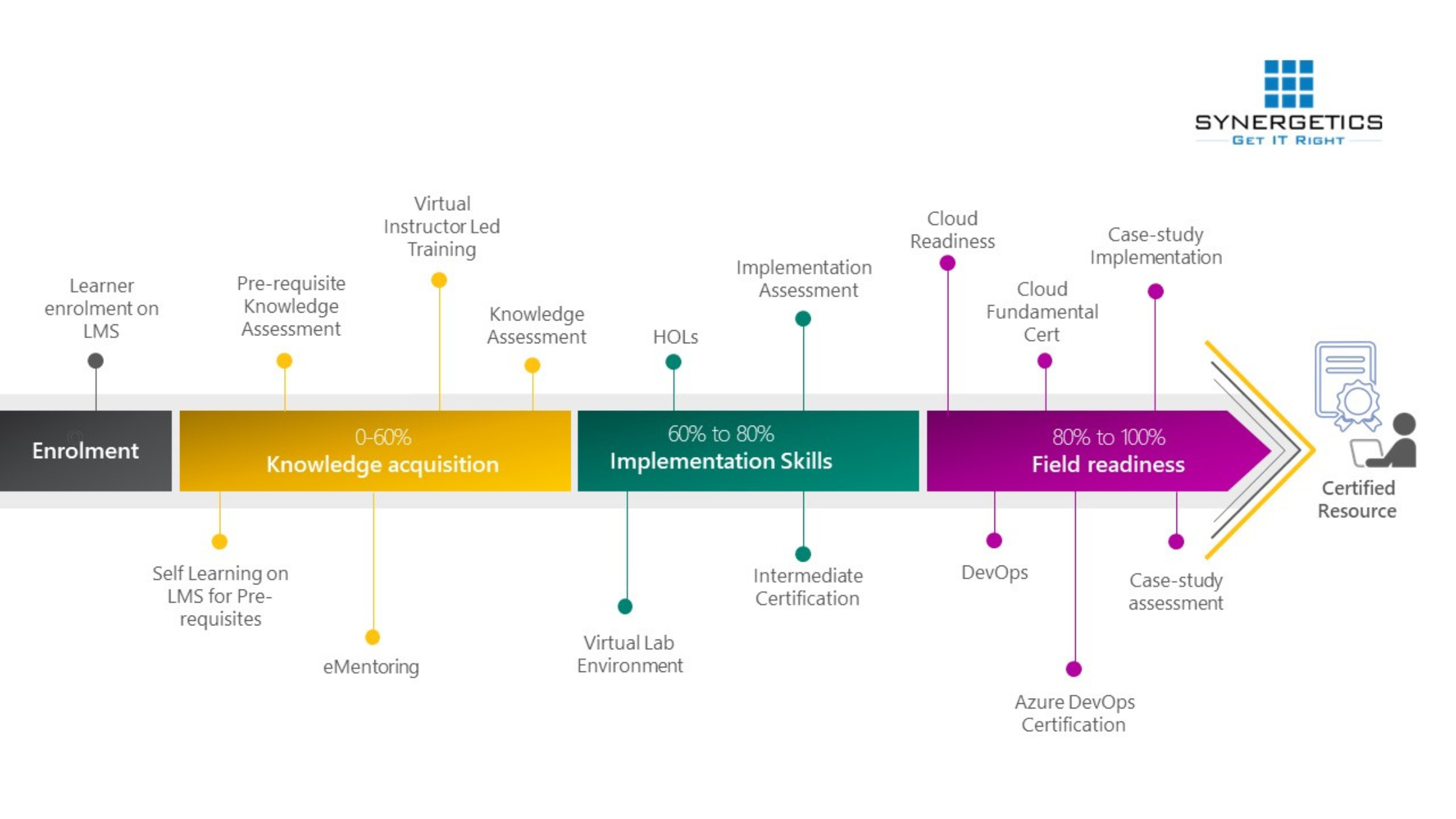
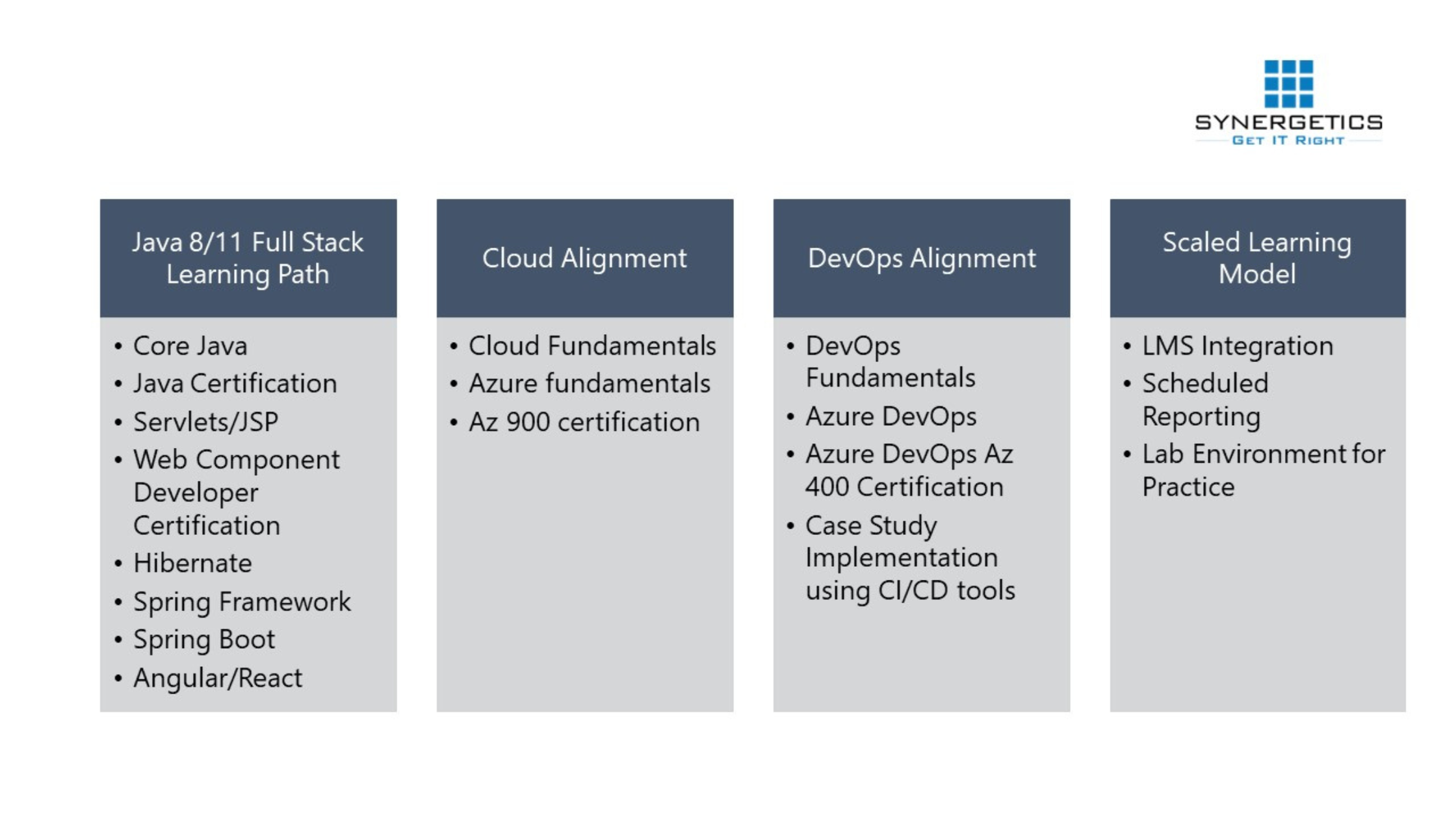
- Ensuring Learning effectiveness in VILT mode
- Training using customized or organization specific content
- Tracking training progress for every individual enrolled in the program.
- Tracking Module wise progress of participants
- Attendance
- Scores of Assignments,
- Assessment (Pretest and Post Test)
- Customizable Grading system
- Gamification using Awards, Badges
- Notification of critical events during the batch
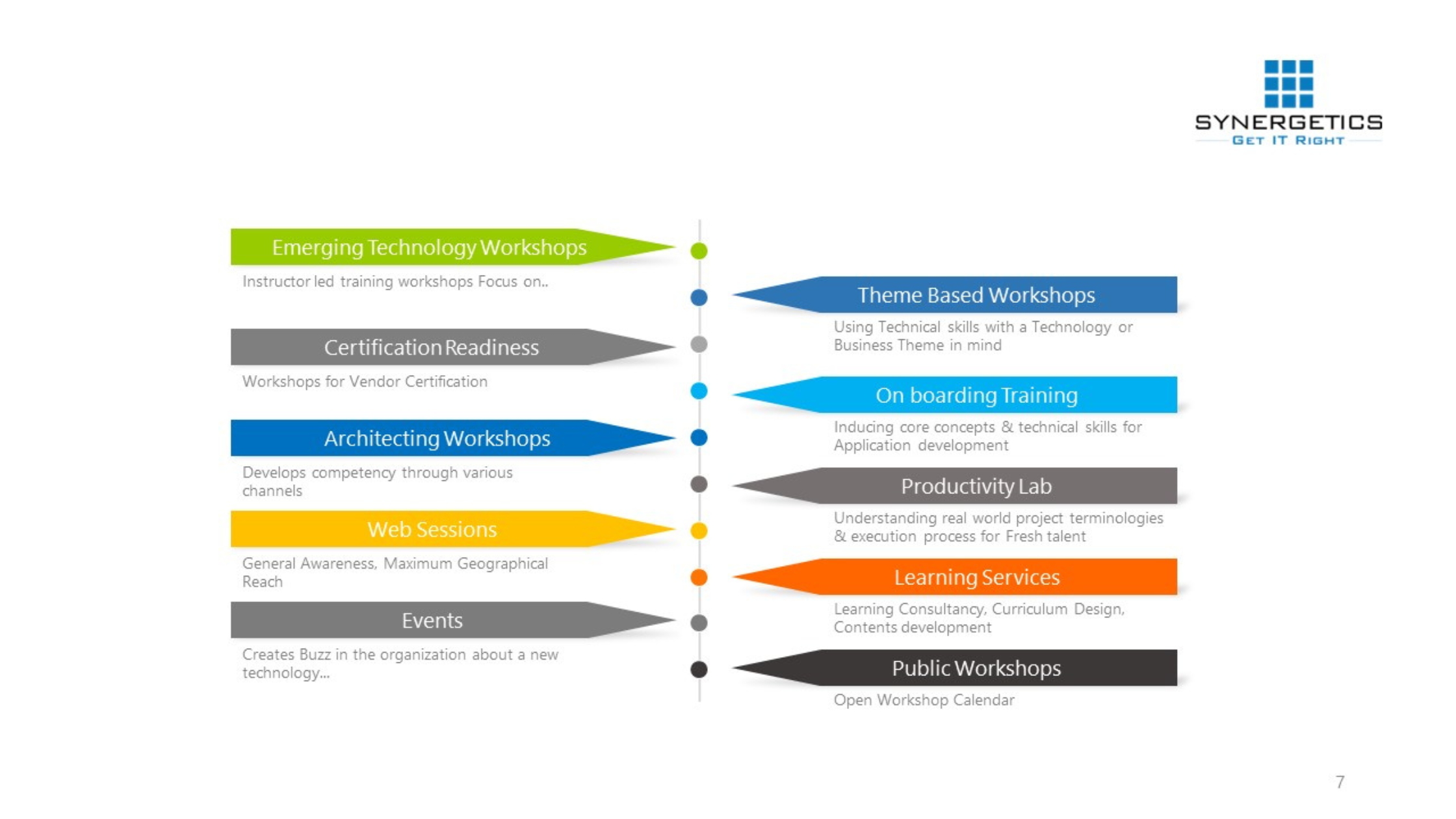
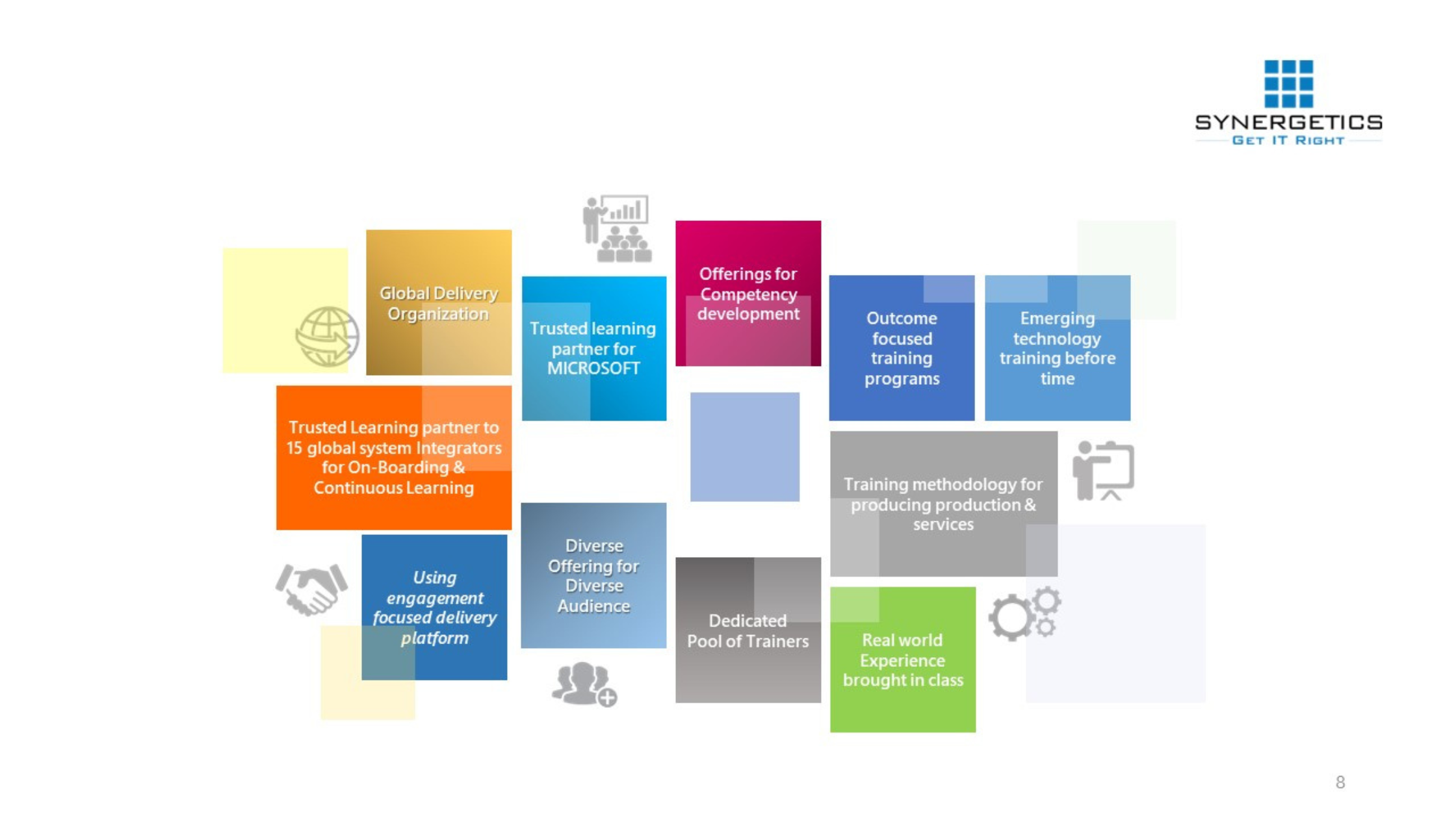
- Trusted Learning Partner for Microsoft for the past 25 years
- Trusted Learning Partner for 15 global system integrators
- A fortified team of certified as well as expert trainers with experience in delivering real-time solutions
- A global delivery organization coupled with competency and outcome focused training
- Specializing in delivery emerging technology training well in advance