Now that you’ve got an idea of what is the technology we are talking about, let’s move on to the OpenAI GPT-3 competitors.
OPT by Meta
Another solid GPT-3 open-source alternative was released by Meta in May 2022. Open Pretrained Transformer language model (OPT for short) contains 175B parameters. OPT was trained on multiple public datasets, including The Pile and BookCorpus.
Its main distinctive feature is that OPT combines both pretrained models and the source code for using or training them.
AlexaTM by Amazon
On November 18, 2022, Amazon publicly released AlexaTM 20B, a large-scale multilingual sequence2sequence model. What’s so special about it? It utilizes an encoder-decoder architecture and was trained on a combo of causal-language-modeling (CLM) and denoising tasks.
Thanks to that, AlexaTM is a better few-shot learner than decoder-only models. As a result, it performs better in 1-shot summarization and machine translation tasks than Google’s PaLM 540B. Also, in zero-shot testing, the model tops GPT-3 on SuperGlue and SQuADv2 datasets.
As for less technical things, AlexaTM supports multiple languages (as its type implies), including English, Spanish, Arabic, German, Hindi, French, Japanese, Italian, Portuguese, and others.
Altogether, this makes AlexaTM quite a notable opponent to all other LLMs, whether free or not.
GPT-J and GPT-NeoX by EleutherAI
GPT-J is a small 6B-parameter autoregressive model for text generation, completely free to use. It was trained on The Pile, a dataset with 22 subsets of more than 800 GB of English texts.
Despite its small size, the model performs nearly the same as GPT-3 6.7B-param and is better than its predecessor, GPT-Neo. The latter had 2 versions, 1.3 and 2.7 billion, and in February 2022 grew into GPT-NeoX, containing 20B parameters.
Here’s a quick overview of how GPT-J and GPT-NeoX perform compared to OpenAI GPT-3 versions.
As you might see, there’s little to no difference in performance between open-source GPT-J and GPT-NeoX and paid GPT-3 models.
Jurassic-1 language model by AI21 labs
Jurassic-1 is an autoregressive natural language processing (NLP) model, available in open beta for developers and researchers.
Yet, it’s not fully open-source, but upon registration, you get $90 credits for free. You can use those credits in the playground with the pre-designed templates for rephrasing, summarization, writing, chatting, drafting outlines, tweeting, coding, and more. What’s more, you can create and train your custom models.
Jurassic-1 might become quite a serious rival to GPT-3, as it consists of 2 parts: J1-Jumbo, trained on over 178B parameters, and J1-Large, consisting of 7B parameters. This already makes it 3B parameters more advanced than GPT-3 language model.
CodeGen by Salesforce
One more open-source GPT-3 alternative you couldn’t miss. As you might have already guessed from its name, CodeGen is a large-scale language model that can write programs, based on plain textual prompts. The model relies on the concept of conversational AI, which aims to unify human creative input with nearly unlimited capabilities of AI coding.
The future of coding is the intersection of human and computer languages — and conversational AI is the perfect bridge to connect the two
CodeGen release comes in three model types (NL, multi, and mono) of different sizes (350M, 2B, 6B, and 16B). Each model type is trained on diverse datasets:
NL models use The Pile.
Multi models are based on NL models and use a corpus with code in various programming languages.
Mono models are based on multi models and use a corpus with Python code.
The most fascinating thing about CodeGen is that even people without any tech background can use it. Still, programming knowledge will help to achieve better and more elegant solutions, as AI isn’t perfect yet.
Megatron-Turing NLG by NVIDIA and Microsoft
This LLM is among the largest ones, as it has over 530B parameters. Megatron-Turing NLG (Natural Language Generation) is a result of collaboration between Microsoft and NVIDIA. To train the model, they used The Pile dataset and NVIDIA DGX SuperPOD-based Selene supercomputer.
The research that was released in October 2021 found that Megatron-Turing NLG is especially good at PiQA dev set tasks and LAMBADA test set tasks. The model also predicts on average over 50% in zero-shot tests and improves those numbers in one- and four-shot tests.
At the moment, Microsoft and NVIDIA offer early access to Megatron-Turing NGL and invite other companies to join them for research. Their main goal is to develop policies of responsible AI usage and eliminate wrong responses, toxicity, and bias in large language models.
LaMDA by Google
LaMDA is an autoregressive Language Model for Dialog Applications, with a decoder-only architecture. Except for chit-chatting on different topics, the model can also create lists and can be trained to talk on some domain-specific topics.
Dialog models can easily scale and can cope with long-term dependencies. This means that they can take into account the previous context, not just the current input. Also, they support domain grounding.
For instance, Google researchers preconditioned LaMDA on several rounds of role-specific dialogs so that it could recommend music. Here’s one of the results:
LaMDA music recommendations example
LaMDA was trained on a 1.56T words dataset, which contained not only public dialog data but also other public texts. The biggest model version has 137B parameters.
Google is making it public, but to access the model, you need to join the waitlist.
BLOOM
The BLOOM autoregressive LLM was developed by multiple contributors through the BigScience Workshop as the GPT-3 open-source alternative. More than 1000 AI researchers joined the project, including specialists from Microsoft, NVIDIA, PyTorch, and others. The BLOOM is available to any individual or team of researchers who want to study the performance and behavior of the large language models and agree with the model’s licensing terms.
The model was trained on 176B parameters from March to July 2022 and can cope with 46 languages and 13 programming languages. Also, it has smaller versions that contain fewer parameters.
The BLOOM has a decoder-only architecture, as it was created based on Megatron-LM, the 8.3B-parameter predecessor of Megatron-Turing NLG.
BERT by Google
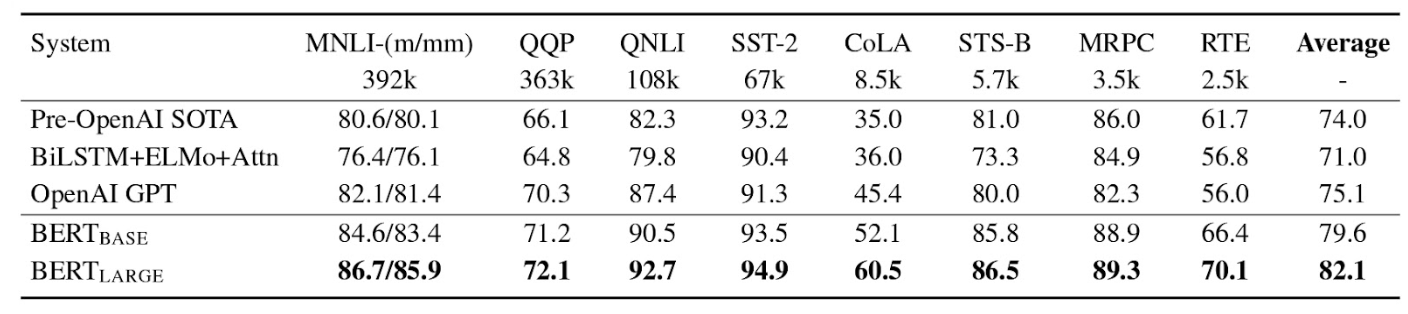
BERT (Bidirectional Encoder Representations from Transformers) is one of the oldest transformer language models, open-sourced in 2018 and pretrained on texts from Wikipedia. Since 2019, Google has been using it to better understand search intent and offer more relevant queries prediction.
By nature, BERT is a bidirectional, unsupervised language representation. This means to continue the sentence, the model takes into account the previous context and the conditions that will follow it.
When first introduced, BERT was tested against other models and showed quite superior results. For example, here’s the performance of the model on the GLUE Test:
GLUE Test results for Pre-OpenAI SOTA, BiLSTM+ELMo+Attn, and OpenAI GPT, BERTBASE, and BERTLARGE (numbers under task names mean the number of training examples)
BERT can be used as a technique for training diverse state-of-the-art (SOTA) NLP models, like question-answer systems, etc.
[Bonus] 3 Additional GPT-3 Alternative Models Worth Attention
These models are not available to the public yet, but look quite promising. Let’s overview what makes them stand out among the competitors.
GLaM by Google
GLaM is the Generalist Language Model, developed by Google. It was introduced in December 2021 and has 1.2T of parameters, which makes it one of the largest existing models. Though Google hasn’t provided public access to its source code, the model itself is noteworthy.
Its key peculiarity is that it is a mixture of experts model (MoE). It consists of multiple layers or submodels (which are called experts), specializing in different domains. Depending on the input data, a gating network picks the most relevant experts (normally, two for each word or its part). Yet, this means the model doesn’t use its capacity to the fullest; it usually activates around 97B of parameters during inference.
Zero-shot and one-shot testing against 29 public NLP benchmarks in natural language processing (NLG) and natural language understanding (NLU) has shown that GLaM prevails over GPT-3.
The tests included natural language interference (NLI), Winograd-style tasks, in-context reading comprehension, commonsense reasoning, open-domain questions answering, and others.
Here are the results of the evaluation:
Results of GLaM and GPT-3 completing NGL and NLU tasks
Wu Dao 2.0
Wu Dao (which translates from Chinese as “road to awareness”) is a pretrained multimodal and multitasking deep learning model, developed by the Beijing Academy of Artificial Intelligence (BAAI). They claim it to be the world’s largest transformer, with 1.75 trillion parameters. The first version was released in 2021, and the latest came out in May 2022.
Wu Dao was trained in English, using The Pile, and in Chinese on a specifically designed dataset that contains around 3.7 terabytes of text and images. Thus, it can process language, generate texts, recognize and generate images, as well as create pictures based on textual prompts. The model has an MoE architecture, like Google GLaM.
BAAI already partnered with such Chinese giants as Xiaomi Corporation and Kuaishou Technology (the owner of the short video social network).
Chinchilla by DeepMind
Chinchilla is a recent compute-optimal language model, introduced in March 2022 by DeepMind, an AI lab, acquired by Google in 2014.
The model itself is only 70 billion parameters in size, but it was trained on 1.4 trillion tokens (text data), which is 4x more compared to the most popular LLMs:
Chinchilla is a recent compute-optimal language model, introduced in March 2022 by DeepMind, an AI lab, acquired by Google in 2014.
The model itself is only 70 billion parameters in size, but it was trained on 1.4 trillion tokens (text data), which is 4x more compared to the most popular LLMs:
1.Language modeling. Chinchilla from 0.02 to 0.10 bits-per-byte improvement in different evaluation subsets of The Pile, compared to Gopher (another DeepMind’s language model).
2. MMLU (Massive Multitask Language Understanding). Chinchilla achieves 67.3% accuracy after 5 shots, while Gopher—60%, and GPT-3—only 43.9%
3.Reading comprehension. Chinchilla demonstrates an accuracy of 77.4% for predicting the final word of the sentence in the LAMBADA dataset, MT-NGL 530B—76.6%, and Gopher—74.5%.
Chinchilla proves it’s the number of training tokens, not the size of parameters, that defines high performance. This discovery potentially opens an opportunity for other models to scale through the amount of info they are trained on, rather than via the number of parameters.
To Sum It Up
For now, we can observe a variety of best AI tools and a breakthrough they make in natural language processing, understanding, and generation. We’ll definitely see even more models of different types coming up in the nearest future.
Here are the alternatives to ChatGPT
Bing with ChatGPT
Google Bard
YouChat
Auto-GPT
StableLM
CatGPT
Poe
AUTO-GPT
(Image credit: AgentGPT)Auto-GPT is a really cool ChatGPT variant, but it takes a bit of coding skill to work. At first glance, it is very similar to ChatGPT, and in fact, it runs on OpenAI’s GPT-4 LLM. But Auto-GPT is semi-autonomous, which is a game-changing feature.
With traditional ChatGPT, you have to do the work of prompting the AI. Say you are trying to build a business plan for a restaurant — you ask ChatGPT the prompt, it gives you a response and then you ask follow-up prompts to fine-tune the plan. But with Auto-GPT, you just set the chatbot a goal of developing the business plan, and then the chatbot will handle setting all the tasks, asking and answering follow-up prompts, etc. It eliminates a significant amount of the work you need to do.
The catch? You need to know how to code with Python. Auto-GPT relies on a Python environment to run. You also need to set up a ChatGPT API account with OpenAI to connect the GPT-4 LLM to the Python environment. So it’s not a simple chatbot to use, unlike the previous three we’ve discussed.
However, there is a way to try out Auto-GPT if you’re not a coding expert. AgentGPT is a free beta that already has the Python environment set up and is connected to the GPT-4 LLM. You can’t do a ton with it — the beta version limits you too how much time you can spend with Auto-GPT — but it still is a great way to try out Auto-GPT. And if you have a ChatGPT API key, you can connect it to AgentGPT and have it use your API key instead of the beta’s API key. We haven’t tried that feature yet though, so proceed at your own risk.
STABLELM
(Image credit: Hugging Face)
Stablity AI is another player in the AI space that competes with Open AI. Its biggest success is the Stable Diffusion AI image generator, but it has now launched an open source LLM called StableLM. You can try it out over at Hugging Face, an AI community site that has a free Alpha test of StableLM running that anyone can try.
Google Bard is Google’s response to ChatGPT, which appears to have caught the search giant totally off guard. Bard uses a combination of two LLMs — Language Model for Dialogue Applications (LaMDA) and Pathways Language Model (PaLM). PaLM in particular gives Bard a boost, bringing improved math and logic capabilities to the AI chatbot.
This chatbot is similar to Bing with ChatGPT and the ChatGPT you can access on Open AI’s site, but its features are a bit more limited. However, Google is regularly updating Bard's features through "Experiment updates" and has even upgraded Bard so that the AI chatbot can now write code. It is also decent as a research tool that you can hold a conversation with, even if it sometimes gets things wrong. We’re hopeful that its feature set will continue to expand as time goes on.
We even compared Bing with ChatGPT versus Google Bard and the results were surprisingly close. While Bing’s chatbot was better at certain things and was more accurate, Bard held its own. We also asked it to answer five controversial sci-fi questions and again, it did a surprisingly good job.
So if you want to try out Google Bard, make sure you get on the Bard waitlist. And use our guide on how to use Google Bard to get the most out of the chatbot.
YOUCHAT
(Image credit: You.com)You.com is a search engine that has actually had an AI chatbot longer than Microsoft’s Bing. Created by former Salesforce employees, the search engine introduced YouChat in December 2022 — upgrading to YouChat 2.0 in February 2023.
The big selling point of YouChat and its LLM called Conversation, Apps and Links (C-A-L) is that it can integrate You.com apps for sites such as Reddit and YouTube into its chatbot’s responses.
YouChat showed some promise when we tested it, but the app integration is not fully there